This is part 6 of the VCP6-DCV Delta Study Guide. It covers availability enhancements in vSphere 6.0. After this section you should be able to describe the new capabilities of vMotion, Fault Tolerance and VMware HA.
- vSphere vMotion Enhancements
- vSphere Fault Tolerance Enhancements
- VMware HA - VM Component Protection
vSphere vMotion Enhancements
In vSphere 6.0 vMotion capabilities have been enhanced by enabling users to perform live migration of virtual machines across virtual switches, vCenter Server systems, and long distances of up to 150ms RTT. vSphere administrators now can migrate across vCenter Server systems, enabling migration from a Windows version of vCenter Server to vCenter Server Appliance or vice versa, depending on specific requirements. Previously, this was difficult and caused a disruption to virtual machine management. It can now be accomplished seamlessly without losing historical data about the virtual machine.
When a virtual machine is migrated across vCenter Server instances, its data and settings are preserved.
This includes the virtual machine UUID, event, alarm, task history, as well as resource settings including shares, reservations, and limits. VMware vSphere High Availability (vSphere HA) and vSphere DRS settings are also retained, including affinity and antiaffinity rules, automation level, start-up priority, and host isolation response. This maintains a seamless experience as the virtual machine moves throughout the infrastructure. MAC addresses are also preserved as they are moved across vCenter Server instances. When a virtual machine is moved out of a vCenter Server instance, the MAC address is added to an internal blacklist to ensure that a duplicate MAC is not generated.
Increasing the latency thresholds for vSphere vMotion enables migration across larger geographic spans,
targeting intracontinental distances. This feature plays a key role for data center migrations, disaster avoidance scenarios, and multisite load balancing.
vMotion Across Virtual Switches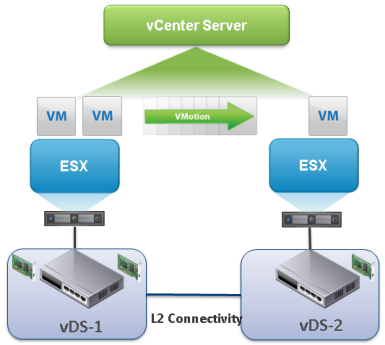
With vSphere 6.0 you can migrate Virtual Machines across virtual switches. The new vMotion workflow allows you to choose the destination network which can be on a vSwitch or vDS. This feature eliminates the need to span virtual switches across two locations. Nevertheless you still have to span the subnet between both locations because vMotion does not change the IP address.
Requirements
- ESX & vCenter 6.0 at both source and destination
- Same SSO domain to use the UI
- Different SSO domain possible if using AP
- 250 Mbps network bandwidth per vMotion operation
- L2 network connectivity on VM network portgroups
The new workflow is integrated to the migration process in the vSphere Web Client. After selecting the compute resource and optionally storage, you can select a new destination network for each VM network adapter.
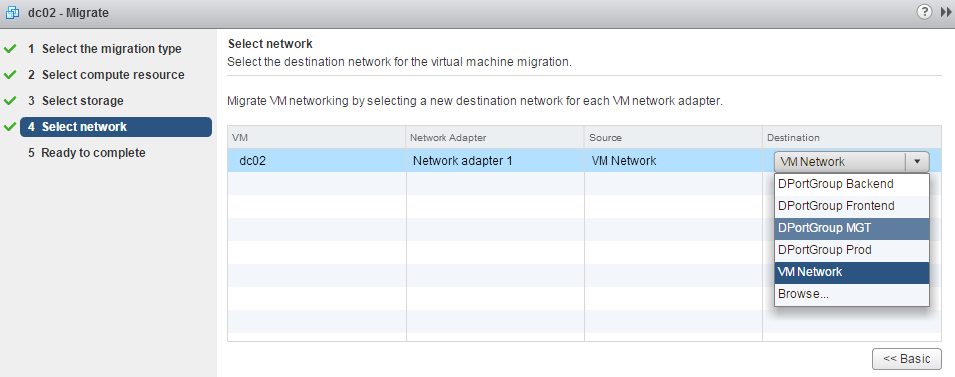
You can migrate between the same type of switches, or from a vSwitch to a vDS. Migrating from vDS to vSwitch is not supported:
"The type of the destination network is not supported for vMotion based on the source network type."
"Network card 'Network adapter 1' has a DVPort backing, which is not supported. This could be because the host does not support VDS or because the host has not joined a VDS."
vMotion Across vCenter Servers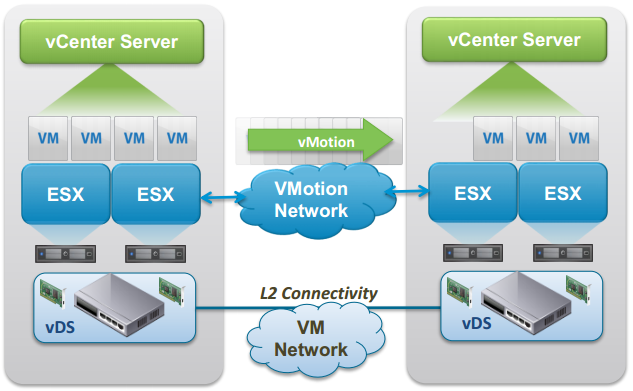
vSphere 6 allows to simultaneously change compute, storage, networks, and management. This enables you to migrate virtual machines across Datacenter and vCenter boundaries. VM Properties are maintained across vCenter Server instances, this includes VM UUID, Events and Tasks History, Alarms, DRS anti-affinity rules and HA properties.
Cross vCenter vMotion triggered by the vSphere Web Client requires both vCenters to be in the same SSO domain. Migration with different SSO domains is possible by using the API.
The new workflow is integrated to the migration process in the vSphere Web Client. Destination resources can be selected in the following sequences:
- Compute resource > Storage > Network
- Storage > Compute resource > Network
- Virtual Datacenter > Storage Policy > Network > Placement Policy
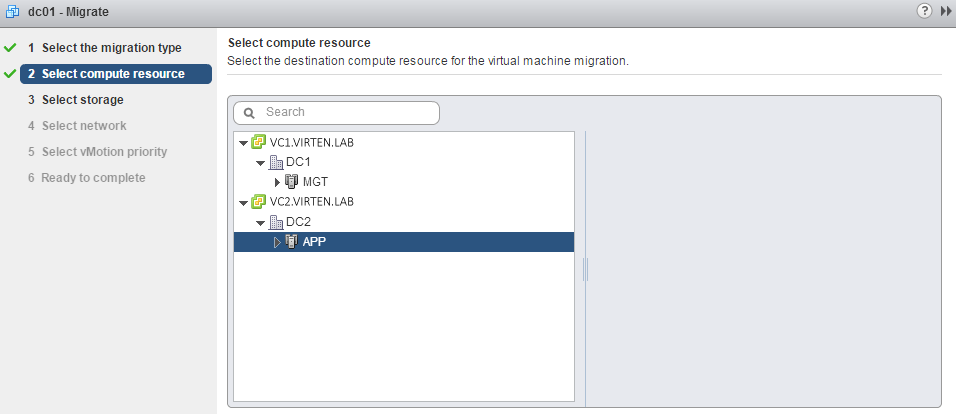 Beside the network, the new part is in the compute resource page where you can chose between all vCenters that are part of the SSO domain.
Beside the network, the new part is in the compute resource page where you can chose between all vCenters that are part of the SSO domain.
Routed Long-Distance vMotion
In vSphere 6.0 vMotion traffic is no longer bound to the same subnet. Routed L3 connections for vMotion traffic are supported. Bandwith requirements are 250 Mbps per concurrent vMotion operation.
 The latency or round-trip time limit for vMotion has been increased to 150ms. What does that means in terms of distance? Optical cables transfer data at the speed of light in glass which is around 200,000 km/s. Thus the maximum distance for a supported round-trip time of 150ms is theoretically 15,000 km. In the real world you have delays caused by switches and routers and the cable is never in a linear distance. Round-trip times that we see in the real world are about 73ms from New York to San Francisco (4100km) and 80ms from New York to Amsterdam (5900km).
The latency or round-trip time limit for vMotion has been increased to 150ms. What does that means in terms of distance? Optical cables transfer data at the speed of light in glass which is around 200,000 km/s. Thus the maximum distance for a supported round-trip time of 150ms is theoretically 15,000 km. In the real world you have delays caused by switches and routers and the cable is never in a linear distance. Round-trip times that we see in the real world are about 73ms from New York to San Francisco (4100km) and 80ms from New York to Amsterdam (5900km).
The requirements for Long Distance vMotion are the same as Cross vCenter vMotion, except with the addition of the maximum latency between the source and destination sites must be 100 ms or less, and there is 250 Mbps of available bandwidth. The VM network will need to be a stretched L2 because the IP of the guest OS will not change. If the destination portgroup is not in the same L2 domain as the source, you will lose network connectivity to the guest OS. This means in some topologies, such as metro or cross-continental, you will need a stretched L2 technology in place. The stretched L2 technologies are not specified. Any technology that can present the L2 network to the vSphere hosts will work, as it’s unbeknown to ESX how the physical network is configured. Some examples of technologies that would work are VXLAN, NSX L2 Gateway Services, or GIF/GRE tunnels.
vSphere Fault Tolerance Enhancements
VMware vSphere Fault Tolerance (vSphere FT) provides continuous availability for applications in the event of physical server failures by creating a live shadow instance of a virtual machine that is always up to date with the primary virtual machine. In the event of a hardware outage, vSphere FT automatically triggers failover, ensuring zero downtime and preventing data loss. vSphere FT is easy to set up and configure and does not require any OS-specific or application-specific agents or configuration. It is tightly integrated with vSphere and is managed using vSphere Web Client.
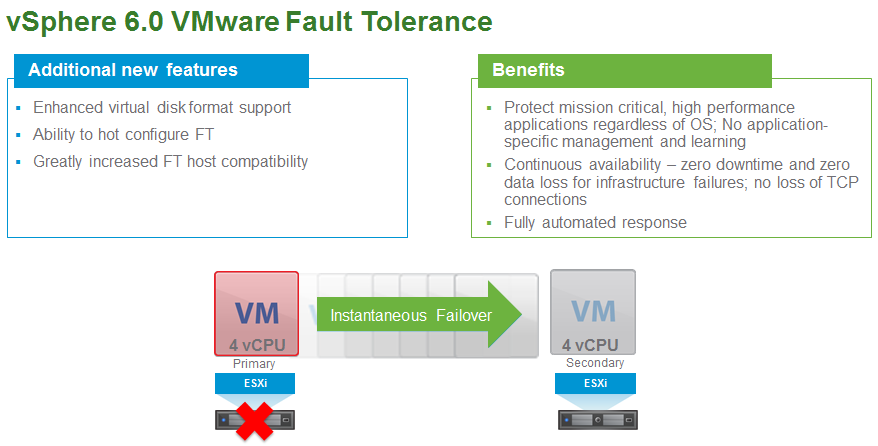
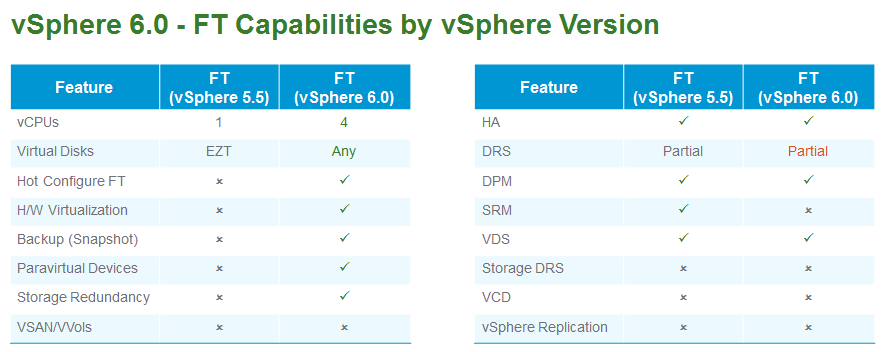
Previous versions of vSphere FT supported only a single vCPU. Through the use of a completely new
fast-checkpointing technology, vSphere FT now supports protection of virtual machines with up to four vCPUs and 64GB of memory. This means that the vast majority of mission-critical customer workloads can now be protected regardless of application or OS.
VMware vSphere Storage APIs - Data Protection, can now be used with virtual machines protected by vSphere FT. vSphere FT 6.0 empowers vSphere administrators to use VMware Snapshot–based tools to back up virtual machines protected by vSphere FT, enabling easier backup administration, enhanced data protection, and reduced risk.
There have also been enhancements in how vSphere FT handles storage. It now creates a complete copy of
the entire virtual machine, resulting in total protection for virtual machine storage in addition to compute
and memory. It also increases the options for storage by enabling the files of the primary and secondary
virtual machines to be stored on shared as well as local storage. This results in increased protection,
reduced risk, and improved flexibility.
In addition, improvements have been made to vSphere FT virtual disk support and host compatibility
requirements. Prior versions required a very specific virtual disk type: eager-zeroed thick. They also had very limiting host compatibility requirements. vSphere FT now supports all virtual disk formats: eager-zeroed thick, thick, and thin. Host compatibility for vSphere FT is now the same as for vSphere vMotion.
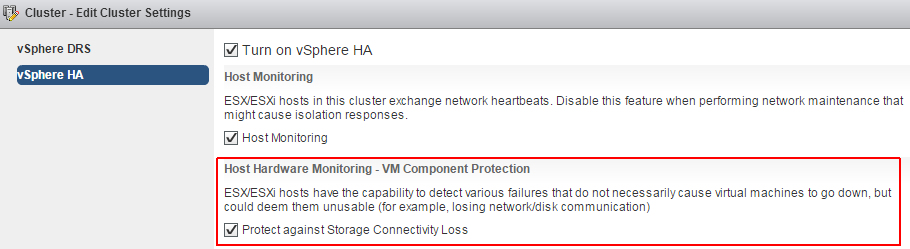
VM Component Protection
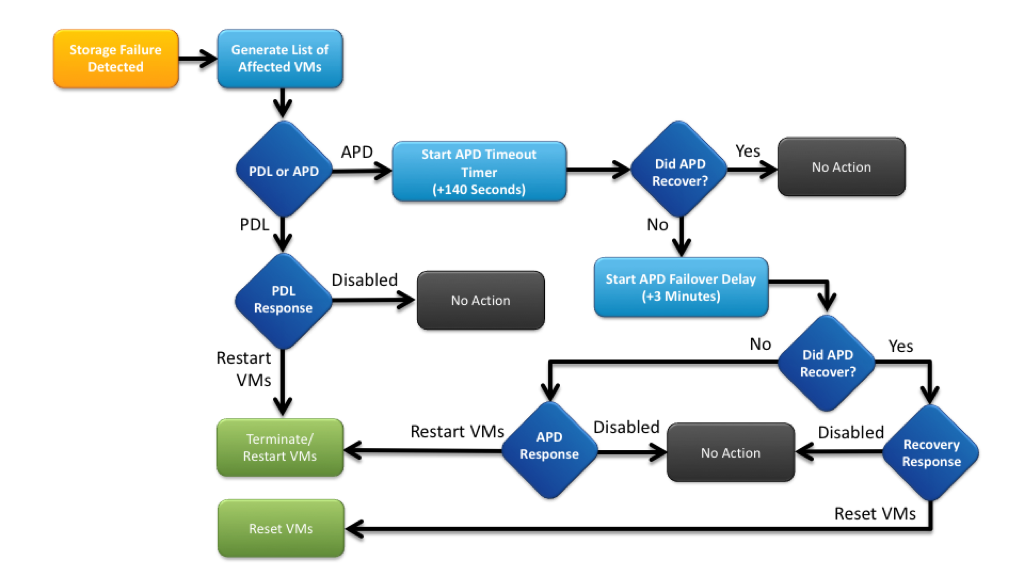
As part of vSphere HA vSphere 6.0 introduces a new feature called VM Component Protection (VMCP). VMCP detect shared storage issues, specifically Permanent Device Loss (PDL) and All Paths Down (APD) incidents. vSphere HA can now respond according to the behavior that you configure. The first step is to enable VMCP in your HA configuration. This settings simply informs the vSphere HA agent that you wish to protect your virtual machines from PDL and APD events.
To activate VMCP navigate to Cluster Settings > vSphere HA and activate the Protect against Storage Connectivity Loss checkbox.
The next step is configuring the way you want vSphere HA to respond to PDL and ADP events. Each type of event can be configured independently. These settings are found on the same window that VMCP is enabled by expanding the Failure conditions and VM response section.

Permanent Device Loss (PDL)
A PDL event occurs when the storage array issues a SCSI sense code indicating that the device is unavailable. A good example of this is a failed LUN, or an administrator inadvertently removing a WWN from the zone configuration. In the PDL state, the storage array can communicate with the vSphere host and will issue SCSI sense codes to indicate the status of the device. When a PDL state is detected, the host will stop sending I/O requests to the array as it considers the device permanently unavailable, so there is no reason to continuing issuing I/O to the device.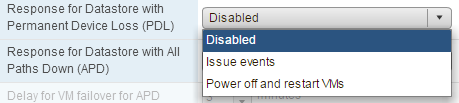
- Disabled - No action will be taken to the affected VMs.
- Issue events - No action will be taken against the affected VMs, however the administrator will be notified when a PDL event has occurred.
- Power off and restart VMs - All affected VMs will be terminated on the host and vSphere HA will attempt to restart the VMs on hosts that still have connectivity to the storage device.
All Paths Down (APD)
If the vSphere host cannot access the storage device, and there is no PDL SCSI code returned from the storage array, then the device is considered to be in an APD state. This is different than a PDL because the host doesn’t have enough information to determine if the device loss is temporary or permanent. The device may return, or it may not. During an APD condition, the host continues to retry I/O commands to the storage device until the period known as the APD Timeout is reached. Once the APD Timeout is reached, the host begins to fast-fail any non-virtual machine I/O to the storage device. This is any I/O initiated by the host such as mounting NFS volumes, but not I/O generated within the virtual machines. The I/O generated within the virtual machine will be indefinitely retried. By default, the APD Timeout value is 140 seconds.
- Disabled – No Action will be taken to the affected VMs.
- Issue events – No action will be taken against the affected VMs, however the administrator will be notified when an APD event has occurred.
- Power off and restart VMs (conservative) – vSphere HA will not attempt to restart the affected VMs unless it has determined there is another host that can restart the VMs. The host experiencing the APD will communicate with the HA master to determine if there is sufficient capacity to power on the affected workloads. If the master determines there is sufficient capacity, the host experiencing the APD will terminate the VMs so they can be restarted on a healthy host. If the host experiencing the APD cannot communicate with the vSphere HA master, no action will be taken.
- Power off and restart VMs (aggressive) – vSphere HA will terminate the affected VMs even if it cannot determine that another host can restart the VMs. The host experiencing the APD will attempt communicate with the HA master to determine if there is sufficient capacity to power on the affected workloads. If the HA master is not reachable, it will be unknown if there is sufficient capacity available to restart the VMs. In this scenario, the host takes the risk and terminates the VMs so they can be restarted on the remaining healthy hosts. However, if there is not sufficient capacity available, vSphere HA may not be able to recover all of the affected VMs.
VMCP Workflow
VCP6-DCV Delta Study Guide
Part 1 - vSphere 6 Summary
Part 2 - How to prepare for the Exam?
Part 3 - Installation and Upgrade
Part 4 - ESXi Enhancements
Part 5 - Management Enhancements
Part 6 - Availability Enhancements
Part 7 - Network Enhancements
Part 8 - Storage Enhancements