In ESXi 7.0 (Build 15843807) and 7.0b (Build 16324942), there is a known issue with the VMFS6 filesystem. The problem is solved in ESXi 7.0 Update 1. In certain workflows, memory is not freed correctly resulting in VMFS heap exhaustion. You might be affected when your system shows the following symptoms:
- Datastores are showing "Not consumed" on hosts
- Virtual Machines fail to vMotion
- Virtual Machines become orphaned when powered off
- Snapshot creation fails with "An error occurred while saving the snapshot: Error."
In the vmkernel.log, you see the following error messages:
- Heap vmfs3 already at its maximum size. Cannot expand
- Heap vmfs3: Maximum allowed growth (#) too small for size (#)
- Failed to initialize VMFS distributed locking on volume #: Out of memory
- Failed to get object 28 type 1 uuid # FD 0 gen 0: Out of memory
The memory allocated gets freed during VMFS resource allocation which means that creating a thick file on VMFS datastores is an effective workaround. The issue and its workaround are documented in the Knowledge Base article KB80188.
- Create Eager zeroed thick disk on all of the mounted VMFS6 datastores.
# vmkfstools -c 10M -d eagerzeroedthick /vmfs/volumes/datastore/eztDisk
- Delete the Eager zeroed thick disk created in step 1.
# vmkfstools -U /vmfs/volumes/datastore/eztDisk
The Workaround has to be done for each datastore on each host. If you have a large platform, this might be challenging. To save time, you can use this simple one-liner to create and delete the disk.
# for I in $(esxcli storage filesystem list |grep 'VMFS-6' |awk '{print $1}'); do vmkfstools -c 10M -d eagerzeroedthick $I/eztDisk;echo "Removing disk $I/eztDisk"; vmkfstools -U $I/eztDisk; done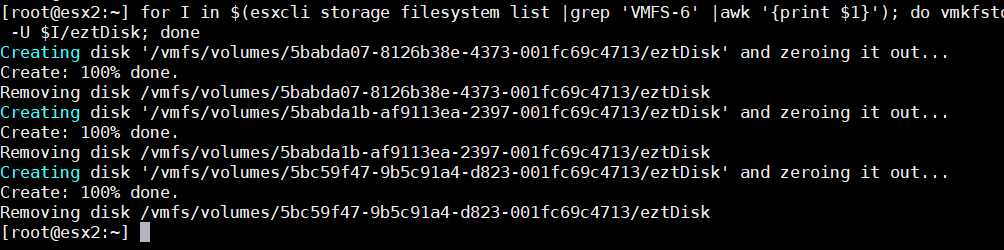
Currently, there is no way to get notified before the heap memory is exhausted. You can apply the workaround at any time as a precaution, even when you are not yet affected.
From my observations, the first indication is the "Maximum allowed growth (#) too small for size (#) error." message in the vmkernel.log If you have a log analysis tool that supports alarming (eg. LogInsight) you can configure an alarm with the following string to get quickly informed when an ESXi host is exhausted:
"Maximum allowed growth * too small for size"