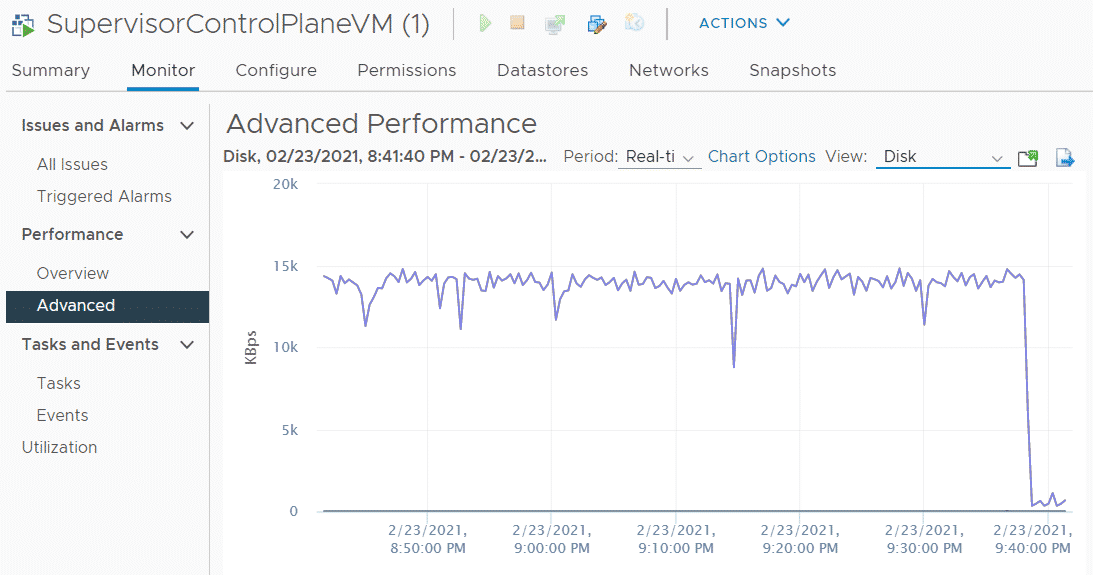
After deploying the latest version of VMware vSphere with Tanzu (vCenter Server 7.0 U1d / v1.18.2-vsc0.0.7-17449972), I noticed that the Virtual Machines running the Control Plane (SupervisorControlPlaneVM) had a constant disk write IO of 15 MB/s with over 3000 IOPS. This was something I didn't see in previous versions and as this is a completely new setup with no namespaces created yet, there must be an issue.
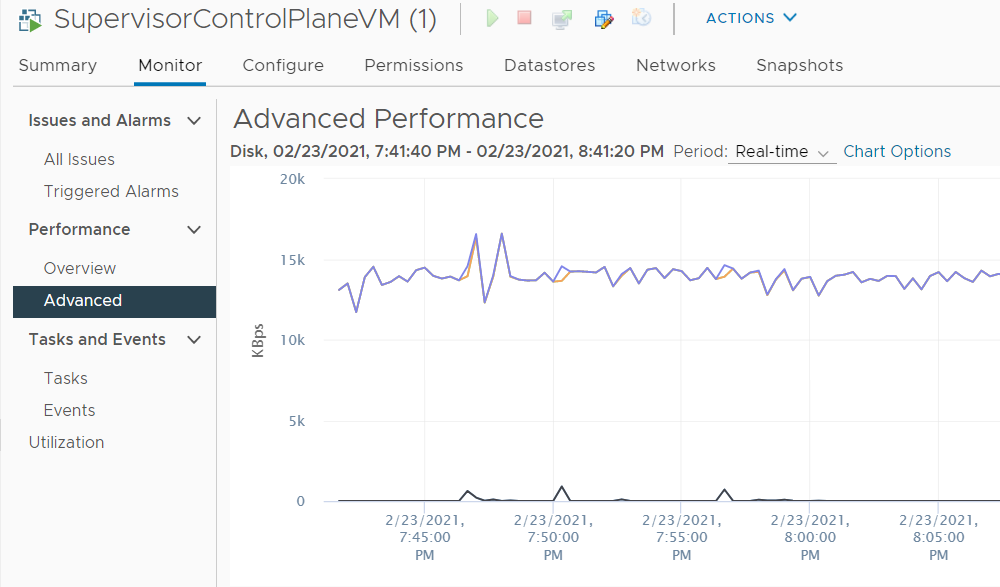
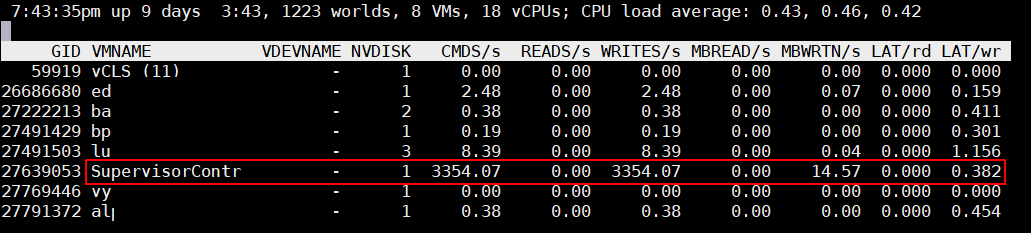
After troubleshooting the Supervisor Control Plane, it turned out that the problem was caused by fluent-bit, which is the Log processor used by Kubernetes. The log was constantly spammed with debugging messages. Reducing the log level solved the problem for me.
[Update: 2021-03-14 - The problem is not resolved in vSphere 7.0 Update 2]
Disclaimer: Manipulating the Supervisor Control Plane is not supported by VMware. If you encounter this problem in production, please open an SR and ask for assistance.
Option 1 - Reduce fluentbit Log Level
Step 1 - Connect to the Control Plane
At first, you have to gain SSH access to the Supervisor Control Plane. The root password can be easily retrieved from the vCenter Server by running the following script on the vCSA:
root@vcenter [ ~ ]# /usr/lib/vmware-wcp/decryptK8Pwd.py Read key from file Connected to PSQL Cluster: domain-c46:def22104-2b40-4048-b049-271b1de46b94 IP: 192.168.250.50 PWD: WpDPx87AQpMerTZ0nUN9CUlc6GmroZglczLp4AGFKd+5bUJEc7XolVfMjt9IBhy7gXIMd9tI ------------------------------------------------------------
Use the password to login to the SupervisorControlPlaneVM as root
ssh root@192.168.250.50
Step 2 - Identify where the Write IO is coming from
Use IOTOP to identify the process that causes the DISK IO.
# yum install iotop -y # iotop
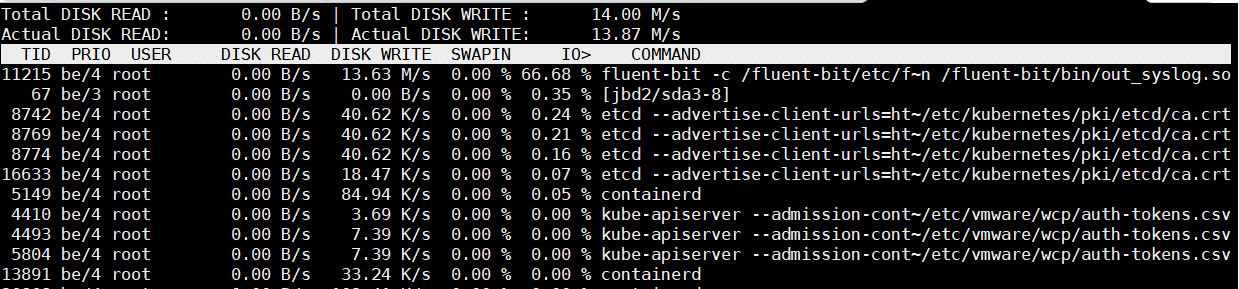
The list is ordered descending by default, so the top consumer is always on top. The fluent-bit process is causing the excessive WRITE IO. The next step is to identify which file the process is writing to. This can't be done easily as there is no tool like iotop for files. You can either use lsof with the process id (#lsof -p 11215), but this is quite annoying as the fluent-bit process has a lot of open files. Another option is the fatrace command, which should easily reveal where the IO is written to.
# yum install fatrace # fatrace [....] containerd(5139): W /var/log/pods/vmware-system-logging_fluentbit-vhlqx_ff9ff5ef-f897-4f91-8252-3adc63603f7d/fluentbit/0.log containerd(5139): W /var/log/pods/vmware-system-logging_fluentbit-vhlqx_ff9ff5ef-f897-4f91-8252-3adc63603f7d/fluentbit/0.log containerd(5139): W /var/log/pods/vmware-system-logging_fluentbit-vhlqx_ff9ff5ef-f897-4f91-8252-3adc63603f7d/fluentbit/0.log containerd(5139): W /var/log/pods/vmware-system-logging_fluentbit-vhlqx_ff9ff5ef-f897-4f91-8252-3adc63603f7d/fluentbit/0.log [...]
Use tail -f to check the log file for errors:
# tail -f /var/log/pods/vmware-system-logging_fluentbit-vhlqx_ff9ff5ef-f897-4f91-8252-3adc63603f7d/fluentbit/0.log 2021-02-23T20:20:40.997113534Z stderr F [2021/02/23 20:20:40] [debug] [input:tail:tail.0] inode=526818 events: IN_MODIFY 2021-02-23T20:20:40.997394121Z stderr F [2021/02/23 20:20:40] [debug] [input:tail:tail.0] inode=526818 events: IN_MODIFY 2021-02-23T20:20:40.99775911Z stderr F [2021/02/23 20:20:40] [debug] [input:tail:tail.0] inode=526818 events: IN_MODIFY 2021-02-23T20:20:40.998904383Z stderr F [2021/02/23 20:20:40] [debug] [input:tail:tail.0] inode=526818 events: IN_MODIFY 2021-02-23T20:20:40.999544395Z stderr F [2021/02/23 20:20:40] [debug] [input:tail:tail.0] inode=526818 events: IN_MODIFY
So...Whatever that is, we need to get rid of it. The message itself does not give a clue what is root cause is, but as it is a debug message, changing the log level should solve the issue for now.
Step 3 - Change fluent-bit Log Level
Fluent-bit is running as a Container in the vmware-system-logging namespace. It's not a typical Linux service that can be configured with configuration files in the /etc/ directory, you have to change it kubernetes-style by editing the ConfigMap.
At first, We need to gather a little bit more information
# kubectl get pods -n vmware-system-logging
NAME READY STATUS RESTARTS AGE
fluentbit-fmlj8 1/1 Running 0 51m
fluentbit-vhlqx 1/1 Running 0 51m
# kubectl describe pod fluentbit-fmlj8 -n vmware-system-logging
Name: fluentbit-fmlj8
Namespace: vmware-system-logging
Priority: 0
Node: 421718a9d6646f3343b49a39e457d8a2/10.244.0.3
Start Time: Tue, 23 Feb 2021 19:35:34 +0000
Labels: controller-revision-hash=7f47679dd7
name=fluentbit
pod-template-generation=3
Annotations: fluentbit.io/exclude: true
kubectl.kubernetes.io/restartedAt: 2021-02-23T19:35:21Z
kubernetes.io/psp: wcp-privileged-psp
Status: Running
IP: 10.244.0.3
IPs:
IP: 10.244.0.3
Controlled By: DaemonSet/fluentbit
[...]
fluentbit-config:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: fluentbit-config
The required information from the output is that fluent-bit is running as DaemonSet with a ConfigMap named fluentbit-config in the vmware-system-logging namespace.
Edit the configmap using kubectl edit:
# kubectl edit configmaps fluentbit-config --namespace vmware-system-logging
In line 10, change the Log_Level to warn
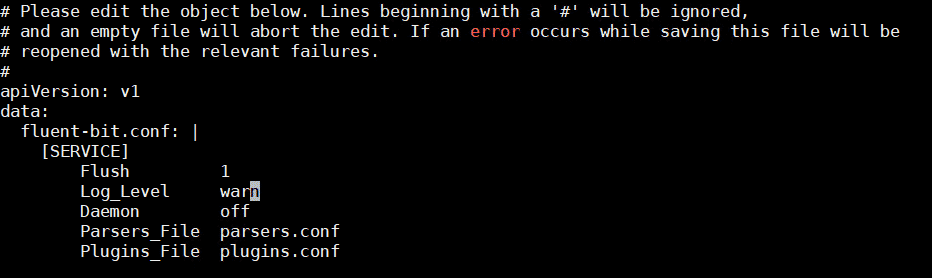
Save the file and quit the editor (ESC :wq! ENTER)
Now you have to restart the container to activate the configuration. This can be done with the kubectl rollout command:
# kubectl rollout restart DaemonSet/fluentbit --namespace vmware-system-logging
That's it. The write and CPU usage should drop immediately. You do not have to change the Log Level on all Virtual Machines. They form a Kubernetes Cluster and the change is rollout out on all nodes automatically.
Option 2 - Disable fluentbit logging
According to a user in VMware's Technology Network, the solution suggested by VMware GSS is to disable fluentbit logging using the vCenters WCP. I've verified the solution and it also solved the issue.
- SSH to the VCSA using the root user
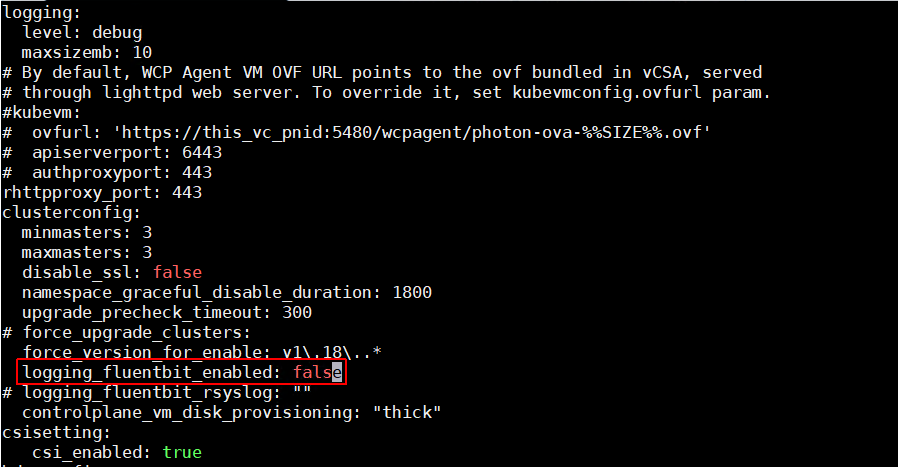
- Edit /etc/vmware/wcp/wcpsvc.yaml and change logging_fluentbit_enabled to false
- Restart the WCP Service
# service-control --restart wcp
Great stuff. I will definitly look into this myself.. our 7U1c with 0.0.6 uses 7000IOPS constantly.. just hadn't gotten around to investigate, so this might be a good place to start!
A simpler fix I got from VMware Support after filing a case:
You can disable fluentbit logging by:
1. ssh into vcsa
2. editing /etc/vmware/wcp/wcpsvc.yaml on the vcsa
change logging_fluentbit_enabled: true => logging_fluentbit_enabled: false
3. service-control --restart wcp
This was really helpful to reduce resource consumption in my Lab environment :-)