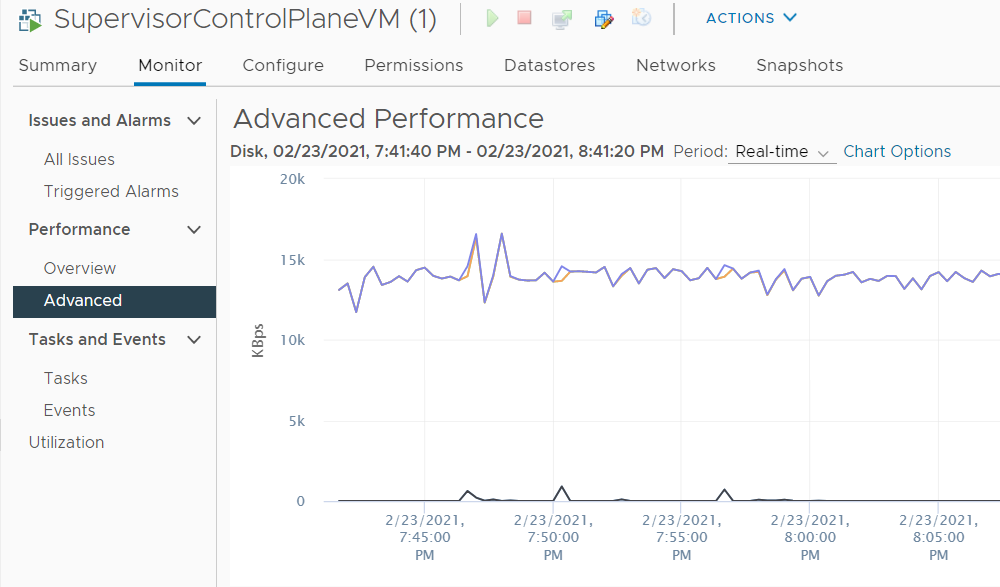
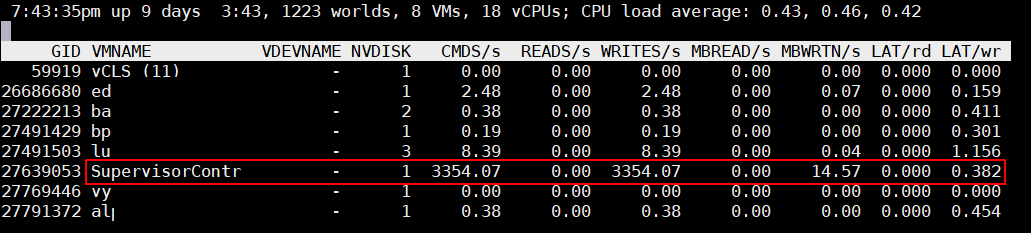
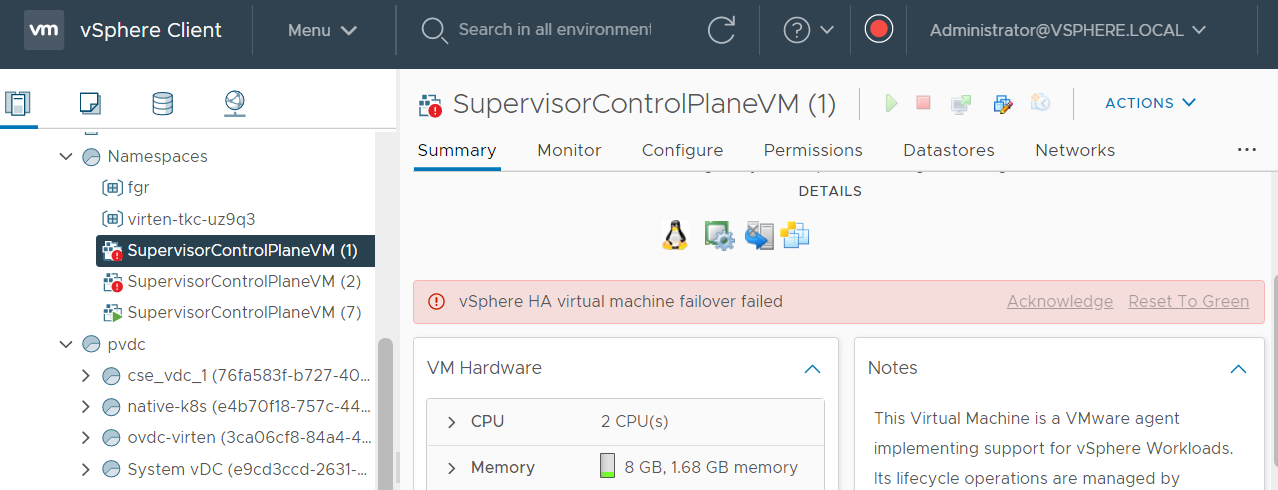
When you try to connect an NSX-T based Segment to a virtual machine, the task fails with the following error message:

Reconfigure virtual machine - An error occurred during host configuration
In the nsx logfile on the ESXi host where the VM is located, the following error is displayed:
/var/log/nsx-syslog.log
2021-03-13T19:00:36Z nsx-opsagent[527252]: NSX 527252 - [nsx@6876 comp="nsx-esx" subcomp="opsagent" s2comp="nsxa" tid="527596" level="ERROR" errorCode="MPA44211"] [PortOp] Failed to create port 780b915d-1479-4eed-8e29-2364d9563f95 with VIF f3f605f2-38a1-4263-bbbd-81b189077f69 because DVS id is not found by transport-zone id 1b3a2f36-bfd1-443e-a0f6-4de01abc963e
2021-03-13T19:00:36Z nsx-opsagent[527252]: NSX 527252 - [nsx@6876 comp="nsx-esx" subcomp="opsagent" s2comp="nsxa" tid="527596" level="ERROR" errorCode="MPA42001"] [CreateLocalDvPort] createPort(uuid=780b915d-1479-4eed-8e29-2364d9563f95, zone=1b3a2f36-bfd1-443e-a0f6-4de01abc963e) failed: Failed to create port 780b915d-1479-4eed-8e29-2364d9563f95 with VIF f3f605f2-38a1-4263-bbbd-81b189077f69 because DVS id is not found by transport-zone id 1b3a2f36-bfd1-443e-a0f6-4de01abc963e
Read More »Error when connecting Virtual Machine to NSX-T Segments

 This article recaps Issues that I had during the integration of VMware Container Service Extension 3.1 to allow the deployment of Tanzu Kubernetes Grid Clusters (TKGm) in VMware Cloud Director 10.3.
This article recaps Issues that I had during the integration of VMware Container Service Extension 3.1 to allow the deployment of Tanzu Kubernetes Grid Clusters (TKGm) in VMware Cloud Director 10.3.